聊聊streamlit库的设计
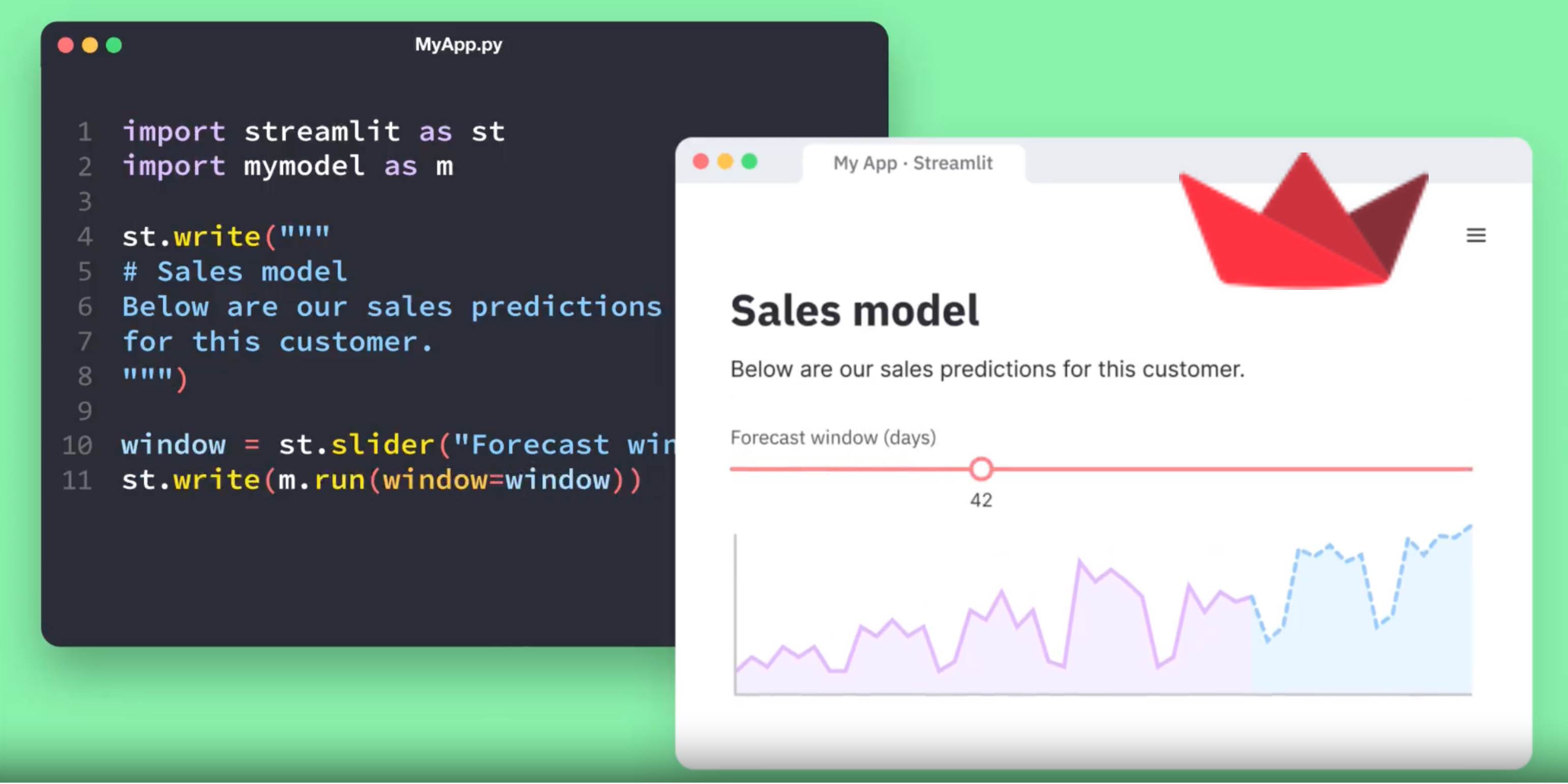
streamlit 库是一个 python 语言的 web app 框架,能够通过简单的代码(无需任何前端基础),快速构建一个带响应式前端的数据展示应用。
响应式在前端领域很常见,streamlit 的创新在于它的前端组件和 python 代码间也是相互绑定的。去年工作需要,我考虑过如何去做更灵活的前后端数据绑定,但没能做得很好。这让我很好奇他们的实现方式。
1. 简单入门 streamlit
https://docs.streamlit.io/get-started/fundamentals/main-concepts
在他们的这个 basic concept 文档中提到几点我们需要注意的:
- 脚本必须由 streamlit 拉起,而不能直接用 python 来执行。这很关键,可以猜测 streamlit 自己做了一些 executor 的活,这个留待后续验证
- 在 Data flow 一节提及:
any time something must be updated on the screen, Streamlit reruns your entire Python script from top to bottom.看来这里是以一整个脚本为粒度进行数据绑定的?这有些意外,它会带来比较大的 overhead,如果能把粒度限制在 variable 级别估计会好很多,但猜想不太好实现 - 在 Display and style data 一节提及:streamlit 可以捕捉脚本里的单行变量或表达式结果来进行展示,被称为
magic commands,这个有些好奇是如何实现的。通常我们使用 python script.py 的方式执行脚本时,这些单行变量和表达式是不会被打印到 stdout/stderr 的,这需要看看是如何做到的 - 各个前端组件可以通过
st.xxxxx(...)的函数来声明,我们可以简单猜测,每个组件按照固定的 template 代码进行生成即可,应该没什么难度。布局相关的组件(layout)同理 - 在最后一小节 "Show progress" 提及,进度条是可以在执行脚本的过程中,实时刷新的。这个特性比较重要,说明我们的脚本必然是被异步执行的,和 streamlit 的 core 中间会有一些 state 传递过程
再接着读一下 advance concept 文档:https://docs.streamlit.io/get-started/fundamentals/advanced-concepts
- 在脚本里可以用
st.cache_data这个 decorator 来修饰需要被缓存结果的函数,这个看起来和我们常用的 lru_cache 没什么两样,但这里比较麻烦的是这个脚本是被 streamlit 的 executor 自己来执行的,需要由 executor 来管理 context,做起来会比较麻烦。st.cache_resource则是用来缓存如 dataset、ML models 等比较大的对象,它俩应该是两种不同的实现思路,需要看看是怎么做的 - Session State 没什么好说的,streamlit 的前后端必然是通过一个个独立的 session 来管理和同步状态的
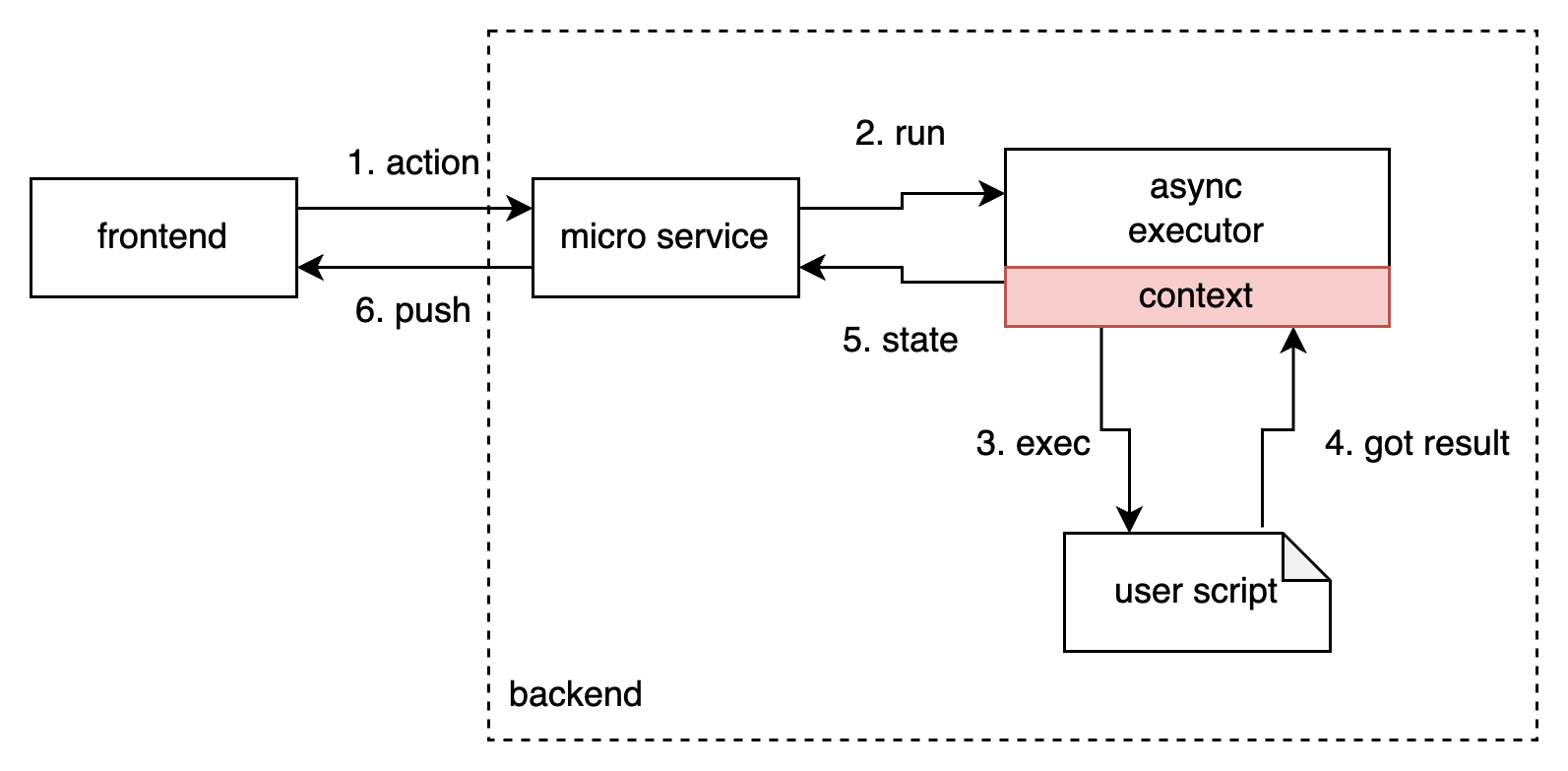
根据上面的猜测,我们大致可以整理出的一个架构图,它还很粗糙,而且不一定正确,我们稍后读一些代码不断验证这个架构:
2. streamlit 入口
位置:streamlit/lib/bootstrap.py
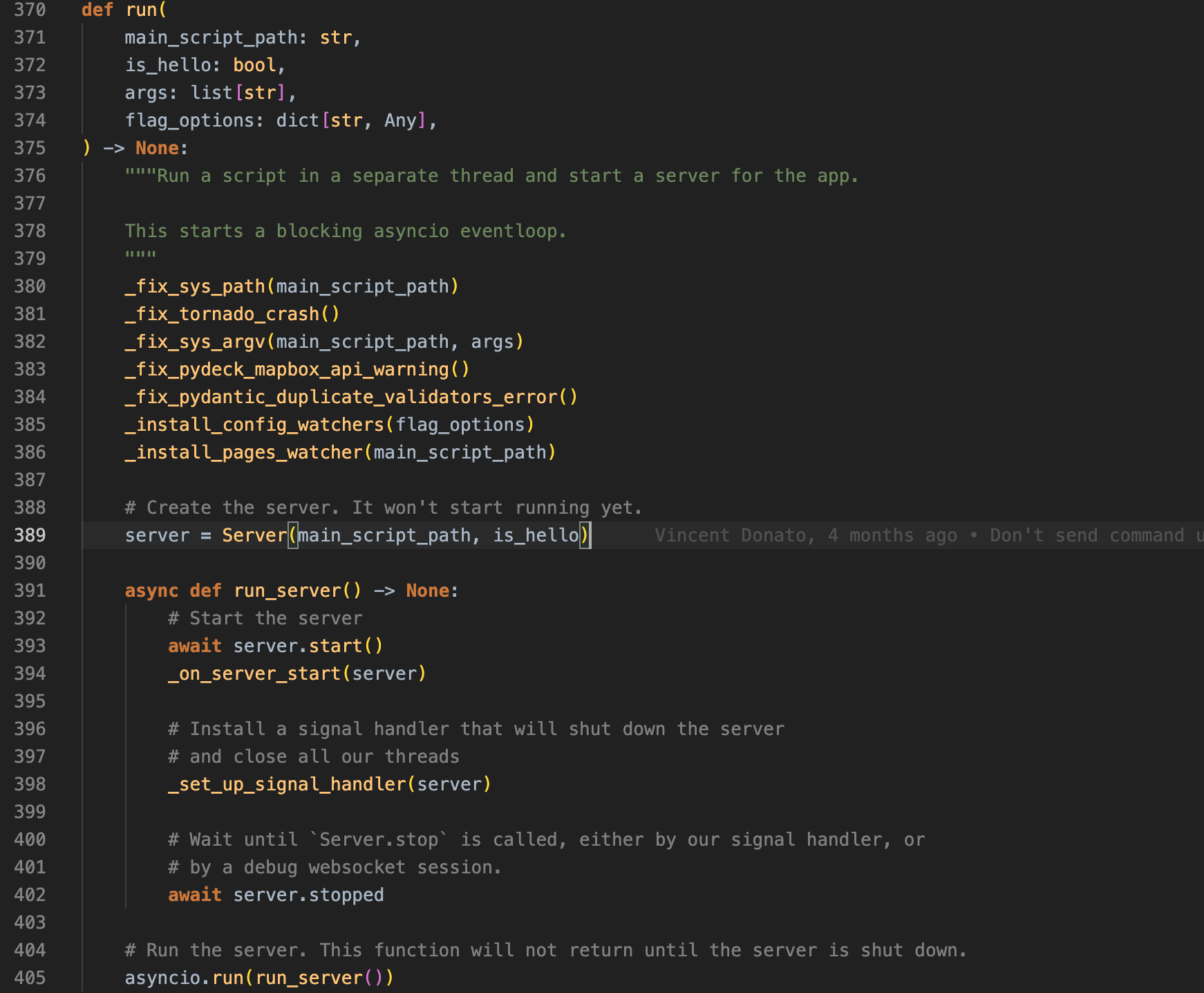
我们首先定位到启动时的命令行参数 streamlit run script.py 上。追踪代码可以看到,在 streamlit/lib/bootstrap.py 中有下面这一段代码。这里可以看到:
- 后端服务框架是 tornado
- 为了避免在用户脚本里的 import 路径问题,需要修正 sys.path
- 为了持续监控用户脚本的更新,需要做一个 page watcher,简单扫一眼代码就知道,维护一个 thread 定时算一下 md5 即可。当然它还实现了 event based 的模式
- 接下来就需要仔细看看这个 Server class 是怎么回事
图片:bootstrap.py 文件的关键入口代码
3. Server 部分
位置:streamlit/web/server/server.py
在这里,我们可以看到两个关键的部分:
- Runtime,猜测很有可能和我们前面提及的 executor、context 相关,后面仔细再看看
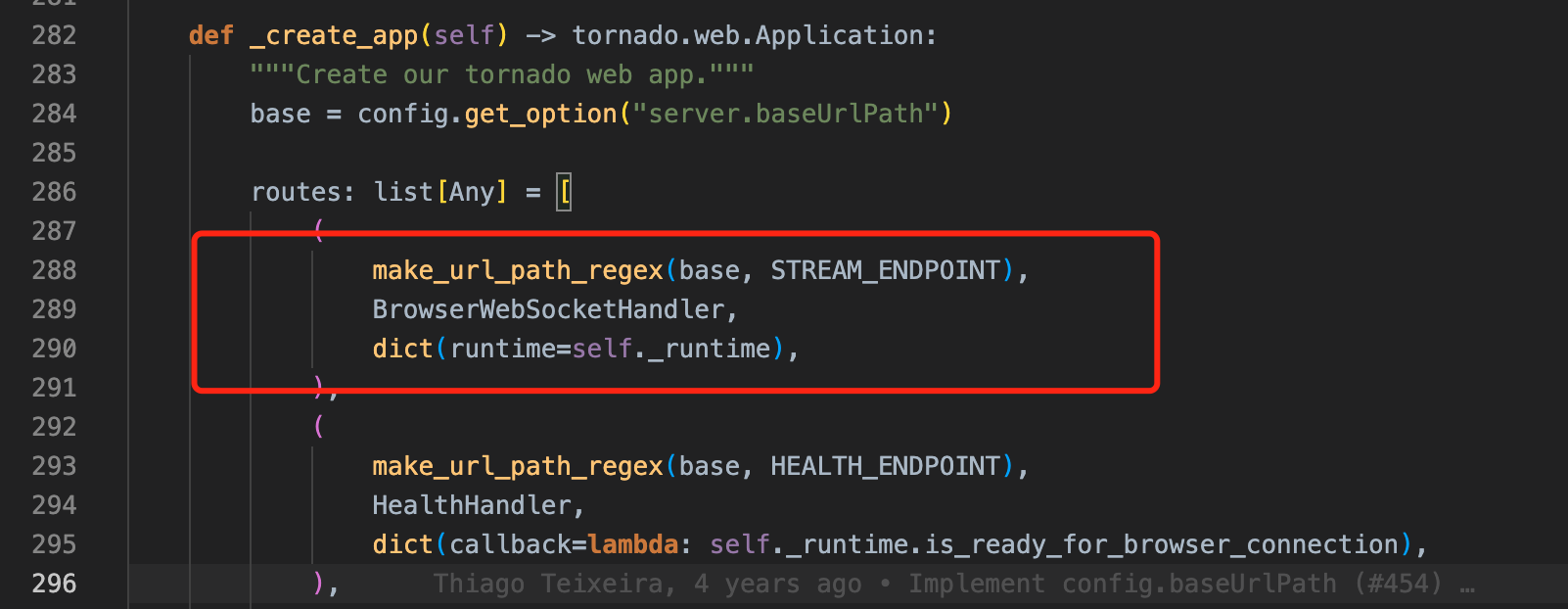
- Tornado 的 Application 实例初始化,尤其是建立一系列的 routers。但粗看下来,没有发现哪个接口是负责串流用户脚本输出内容的。这时候我们可以在前端捕捉一下所有请求,看看具体是哪个接口。
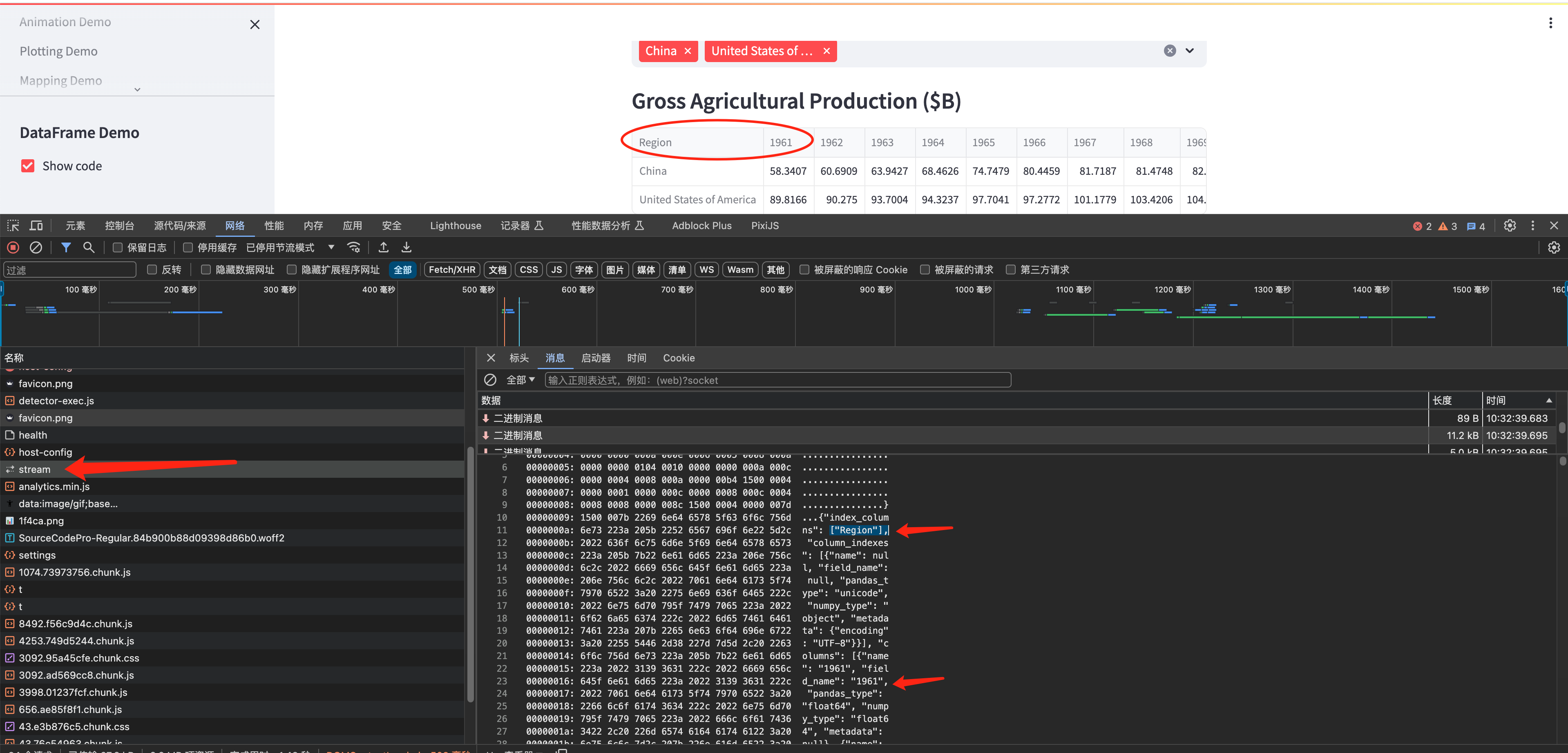
以 DataFrame_Demo 为例,表格的内容是通过一个 websocket 做数据推送的,它的 api 地址是:ws://localhost:8502/_stcore/stream,对应routers 里的第一项内容。而 BrowserWebSocketHandler 实际上只是给 runtime 建立 websocket 连接,把请求解包后丢给 runtime 而已。因此 runtime 才是整个处理过程的关键!
图片:streamlit hello 的 DataFrame_Demo 运行抓包,可以看到 pandas 输出的表格通过 websocket 通道推送至前端
图片:server.py 里创建 tornado Application 时,创建 api routes 部分的关键代码,其中红框是上面提到的 websocket api。
4. Runtime 部分
位置:streamlit/runtime/runtime.py
接下来就是整个框架的重点部分,runtime 了。runtime 内容很多,可以从几个方面来解读。
4.1 状态流转
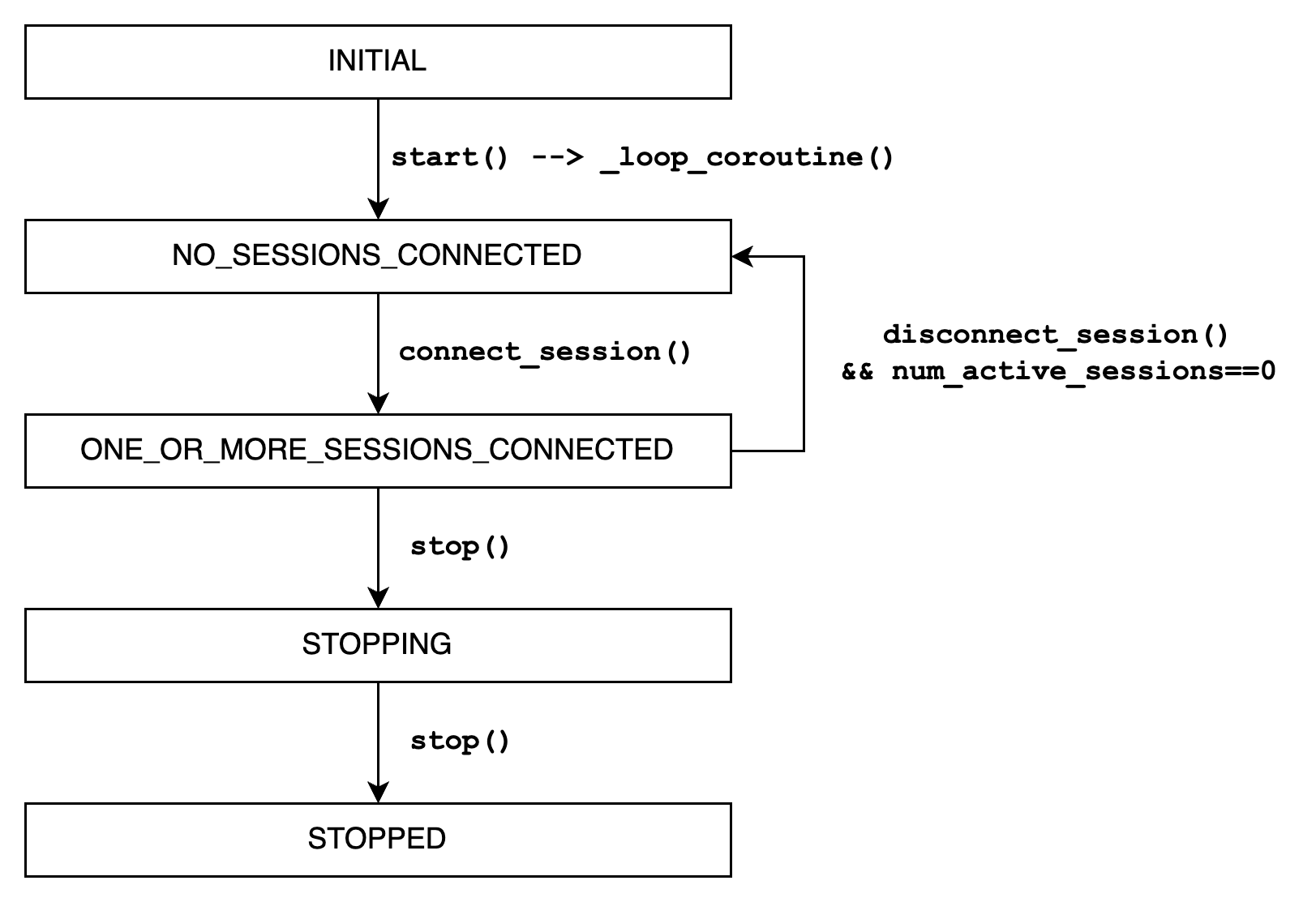
runtime 内部实现了一个简单的状态机,没有复杂的状态跳转,就是从上往下逐个流转。需要注意的是,_loop_coroutine() 是内部的一个 async task,或者说它是独立于主线程外的子线程。外部的调用如 stop()/connect_session()/close_session() 等函数都是外部线程,它们之间通过 _async_objs 内的几个 events 对象做事件通知。
图片:runtime 部分的状态流转过程
4.2 一个 Session 的完整生命周期
1. 创建连接
connect_session() --> WebsocketSessionManager::connect_session() --> create AppSession
目前 SessionManager 仅实现了一个 WebsocketSessionManager,它的实现很简单,就是一个 session 的 holder 而已,每个 connection 维护其对应的 AppSession 实例。从这里暂时未知这个 AppSession 是用来干嘛的,后面再看。
此外,connect_session() 的最后,还通过设置 async_objs.has_connection 通知到 _loop_coroutine() 内的异步线程,启动相应的消息处理流程。
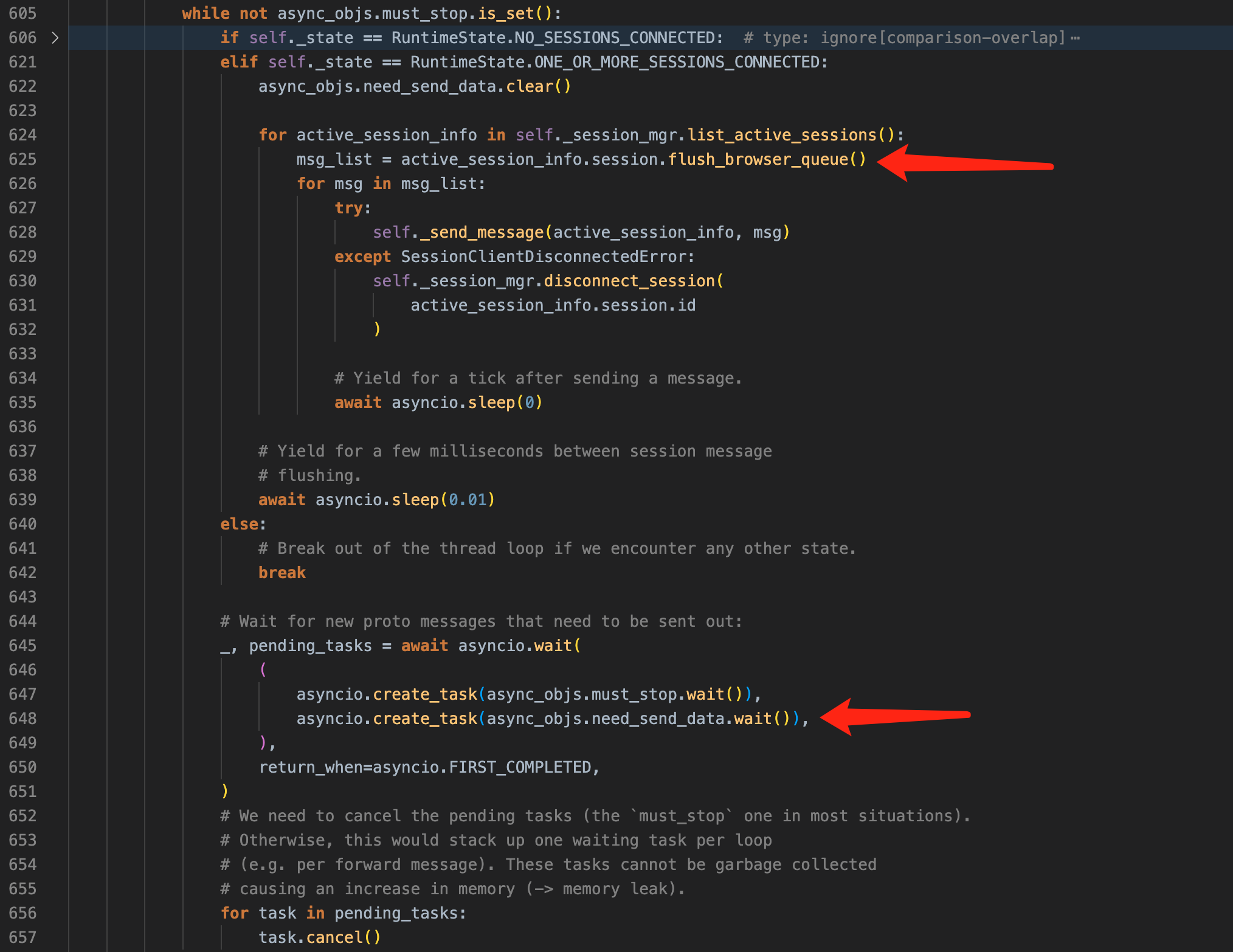
2. 处理连接请求和回写消息
异步线程的主循环代码很简单,当处于 ONE_OR_MORE_SESSIONS_CONNECTED 状态时,不断从 session_mgr 取出活跃的 session,并把待发送的消息回写而已。此时循环的主要驱动事件是 async_objs.need_send_data。runtime 中仅有 _enqueued_some_message() 函数会对该事件置位,而这个函数已经被丢入到 session_mgr 的初始化中,成为一个 callback 函数。
这里我们就可以大胆猜测了:
AppSession是主要的用户脚本运行的地方,它会管理脚本的运行、管理输入数据、结果提取等等- 当用户脚本执行结束后,AppSession 会提取其输出结果,并通过 callback 形式通知到 ``async_objs.need_send_data`,告知 runtime 进行消息回写
- 客户端发来的 websocket 请求体,会通过前面提及的
BrowserWebSocketHandler::on_message()函数,转发到 runtime 的handle_backmsg()函数,而该函数也是简单转发至AppSession::handle_backmsg()函数处
至此,我们可以断定,这个 runtime 并非实际运行用户脚本的地方,它仅仅是用来处理客户端请求,维持连接状态和流转的状态机而已,实际干活的全都在 AppSession 部分。
图片:循环处理客户端请求、回写脚本执行结果
3. 断开连接
runtime 这部分没什么特殊处理,就是把请求转发到了 SessionManager,而 SessionManager 又进一步地把停止请求转发到 AppSession,然后清理掉 SessionManager 内的相关联对象而已。
5. AppSession 部分
位置:streamlit/runtime/app_session.py
前面提及,客户端过来的请求消息,最终转发到了 AppSession::handle_backmsg() 函数处,我们以此为起点。
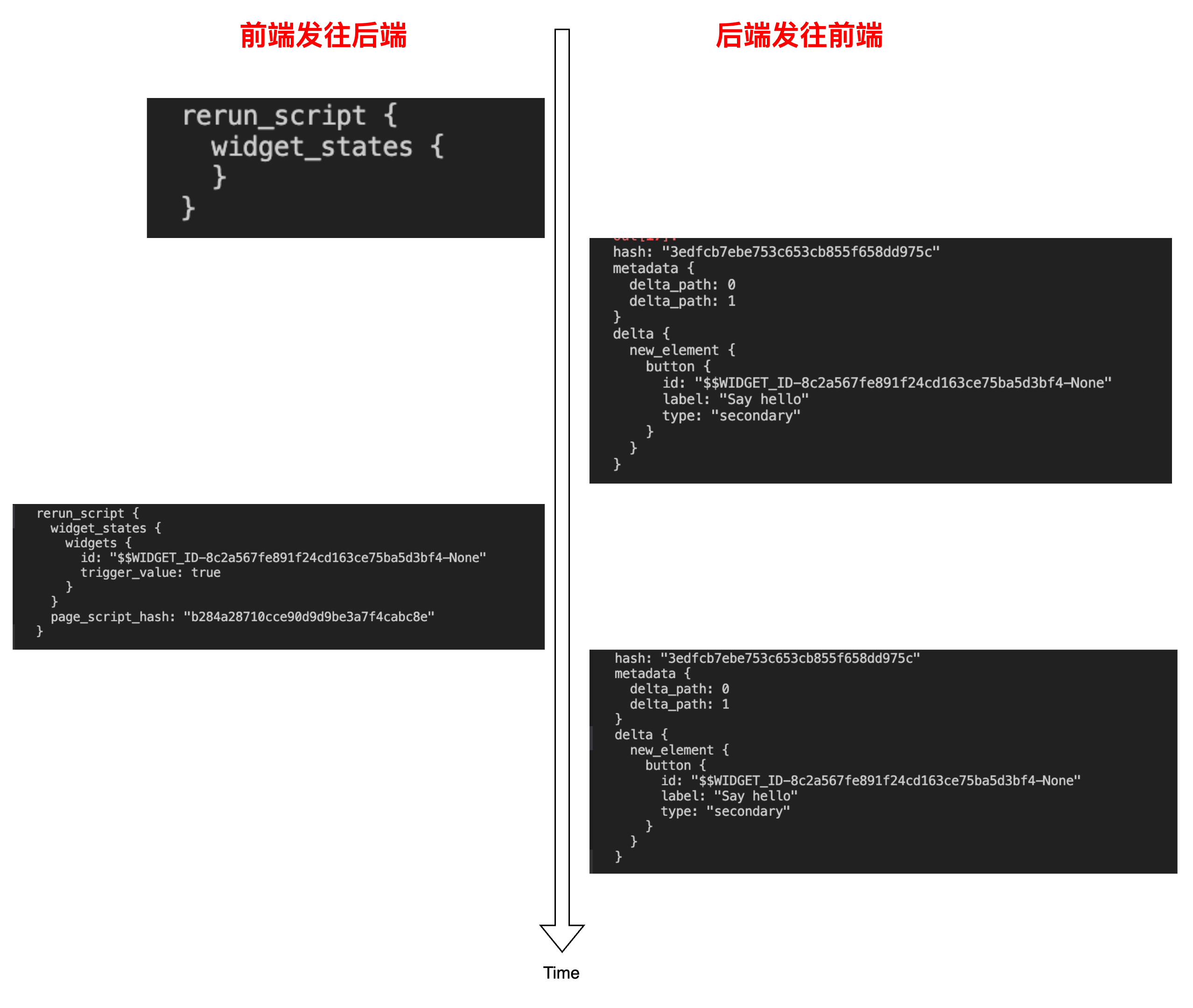
我们尝试解压浏览器抓包拿到的 websocket 第一帧消息体,并用 protobuf 协议解包看看:
图片:客户端首帧请求体
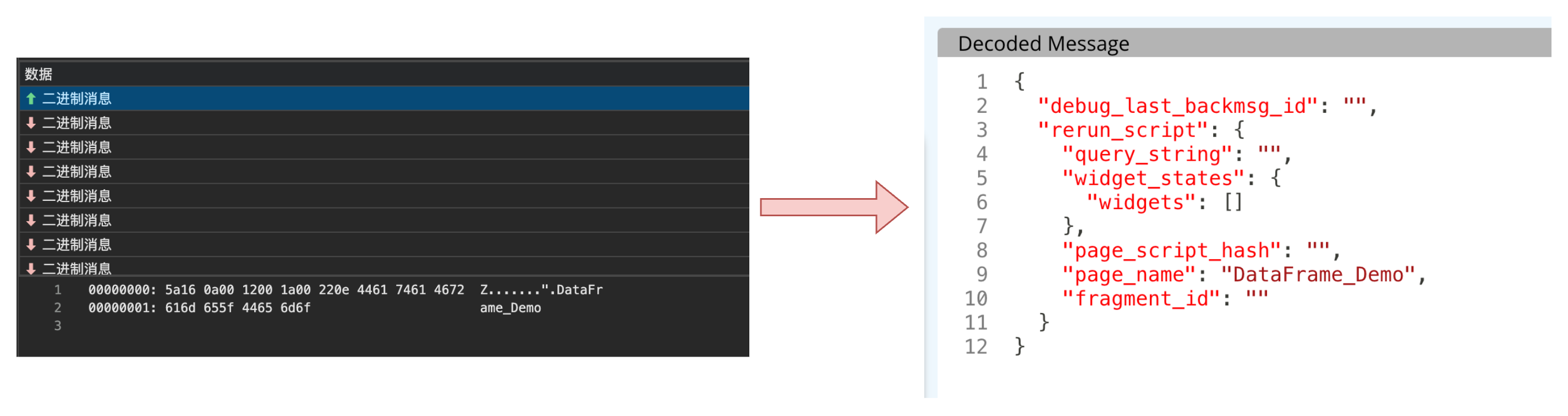
也就是说,第一帧请求过来是执行名为 DataFrame_Demo 的用户脚本,符合猜测。看来我们越来越接近实际的用户脚本执行部分了。
跟着代码走一下,很容易找到这个 ScriptRunner 的初始化部分代码:
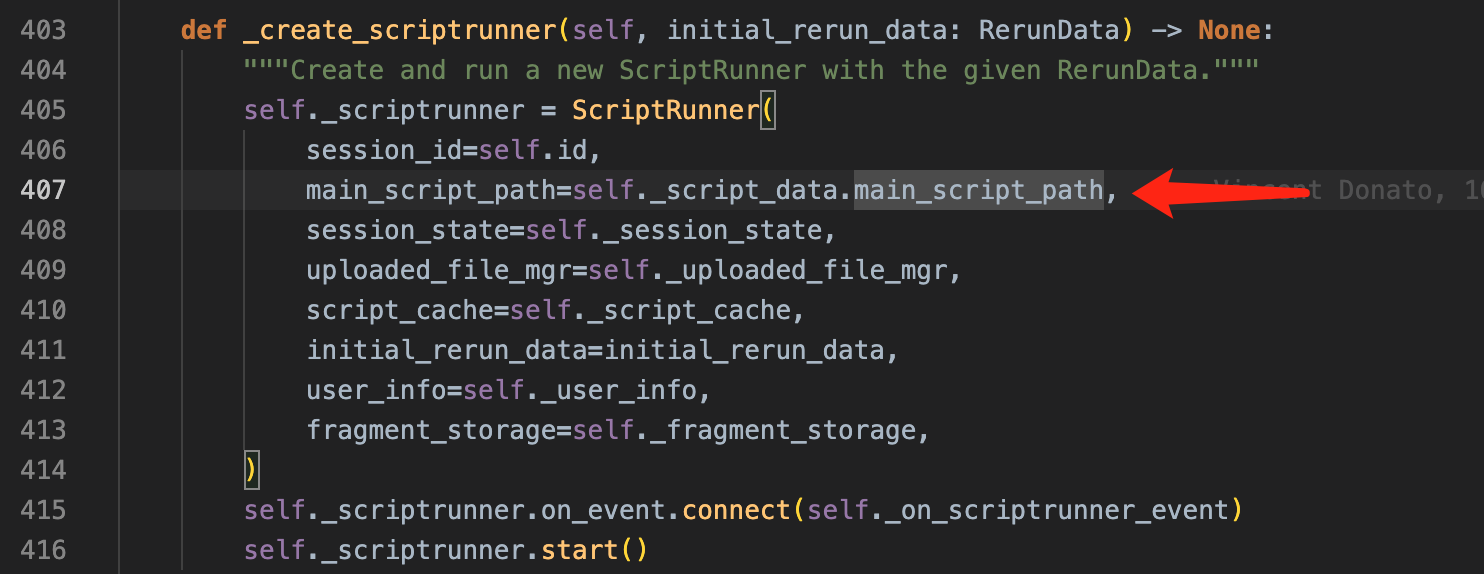
5.1 ScriptRunner
位置:streamlit/runtime/scriptrunner/script_runner.py
在 ScriptRunner 类的最前端,注释明确说明了两种线程类型:
- 主线程:由 streamlit cli 启动的后端服务线程
- 用户脚本线程:由 ScriptRunner 启动的,用来运行用户脚本的专用线程
这个思路很好理解,因为我们无法确定用户脚本会不会 crash,会不会长时间运行等等,因此为了确保服务的稳定,是必然要把它分离开的。只不过我以为用户脚本很可能是在子进程,而非线程中执行,这有些以外。谁说线程崩溃一般比较不太会影响到主线程的运行,但独立的进程会有更好的隔离性,同时也能利用上 cpu 的多核优势。尤其是连接较多时,可以获得更好的性能。
当然这里的猜测有一个前提是,tornado 的 BrowserWebSocketHandler 是运行在核心进程而非子进程内的。如果 tornado 在处理新进 websocket 连接时就已经创建了子进程,那上面的猜测就是错的了。anyway,这里就不过多展开。
在 ScriptRunner 里,整个调用链是这样的:
- 在
AppSession里,通过调用scriptrunner.start()函数,拉起一个新的用户脚本线程 - 新的线程执行
_run_script_thread()函数,与主线程通过ScriptRequests对象进行线程间通信,main loop 里调用_run_script()函数,真正执行用户脚本 - 在
_run_script()里,大致流程是:1. 组装用户脚本运行时的 context;2. 给用户脚本注入一些 helper 函数,入口函数等;3. 调用exec()函数,执行用户脚本
图片:执行用户脚本的核心代码

这里我比较关心的是如何注入必要的函数,来实现 magic commands,以及 ``st.cache_data与st.cache_resource` 两者的区别。
5.2 实现 magic commands
位置:streamlit/runtime/scriptrunner/magic.py
仔细跟踪一下代码,不难发现在 ScriptRunner 里,通过 ScriptCache 实例在调用 get_bytecode() 函数时,一方面把 magic functions 给注入进去,另一方面编译为 bytecodes。因此我们重点关注 magic.add_magic() 的具体实现方法。
add_magic() 的思路是,把代码解析为一颗 ast(abstract syntax tree,抽象语法树),遍历它,一旦遇到 ast.Expr 类型的节点,就能说明它是一个单行表达式,可以转写为 st.write() 调用了。_modify_ast_subtree() 函数里,其他部分主要是根据语法特性,递归遍历这颗树而已:
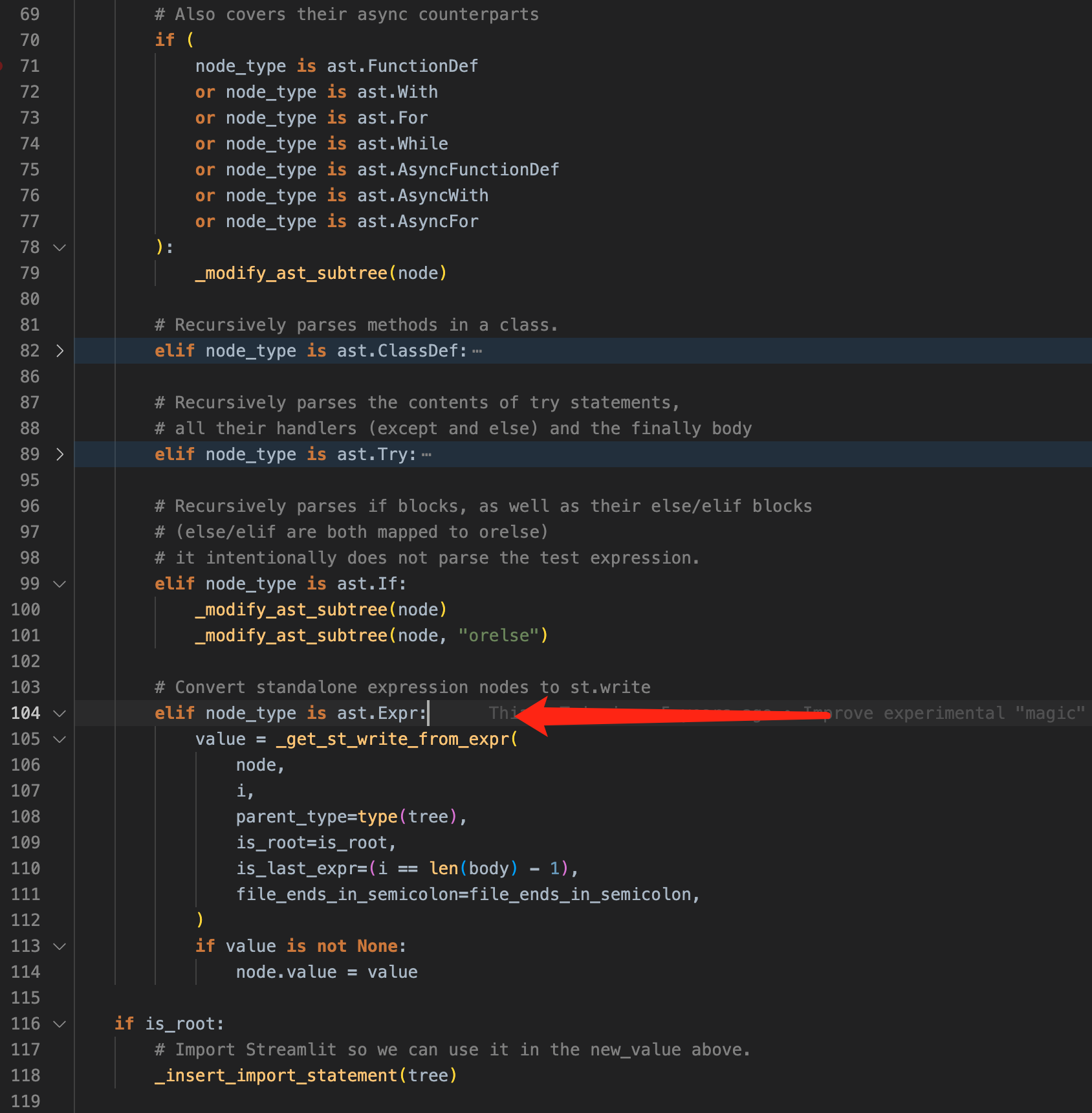
抽象语法树,顾名思义它就是把每个语法部分解析为一颗树上的一个节点,相比源代码,ast 结构规整,遍历、修改都很方便。比如上面的截图里,streamlit 直接把一个单行表达式的节点内容,替换为新的 transparent_write() 函数调用,我们可以做个测试:
from streamlit.runtime.scriptrunner.magic import add_magic
import ast
code = """
import pandas as pd
df = pd.DataFrame({'first column': [1, 2, 3, 4], 'second column': [10, 20, 30, 40]})
df
"""
with open('/tmp/test.py', 'w') as f:
f.write(code)
ret = add_magic(code, '/tmp/test.py')
print(ast.unparse(ret))
## 输出为:
import pandas as pd
import streamlit.runtime.scriptrunner.magic_funcs as __streamlitmagic__ # <-- import 注入
df = pd.DataFrame({'first column': [1, 2, 3, 4], 'second column': [10, 20, 30, 40]})
__streamlitmagic__.transparent_write(df) # <-- 被替换为 transparent_write() 函数了
关键被替换的两行代码,其 ast 注入方式是:
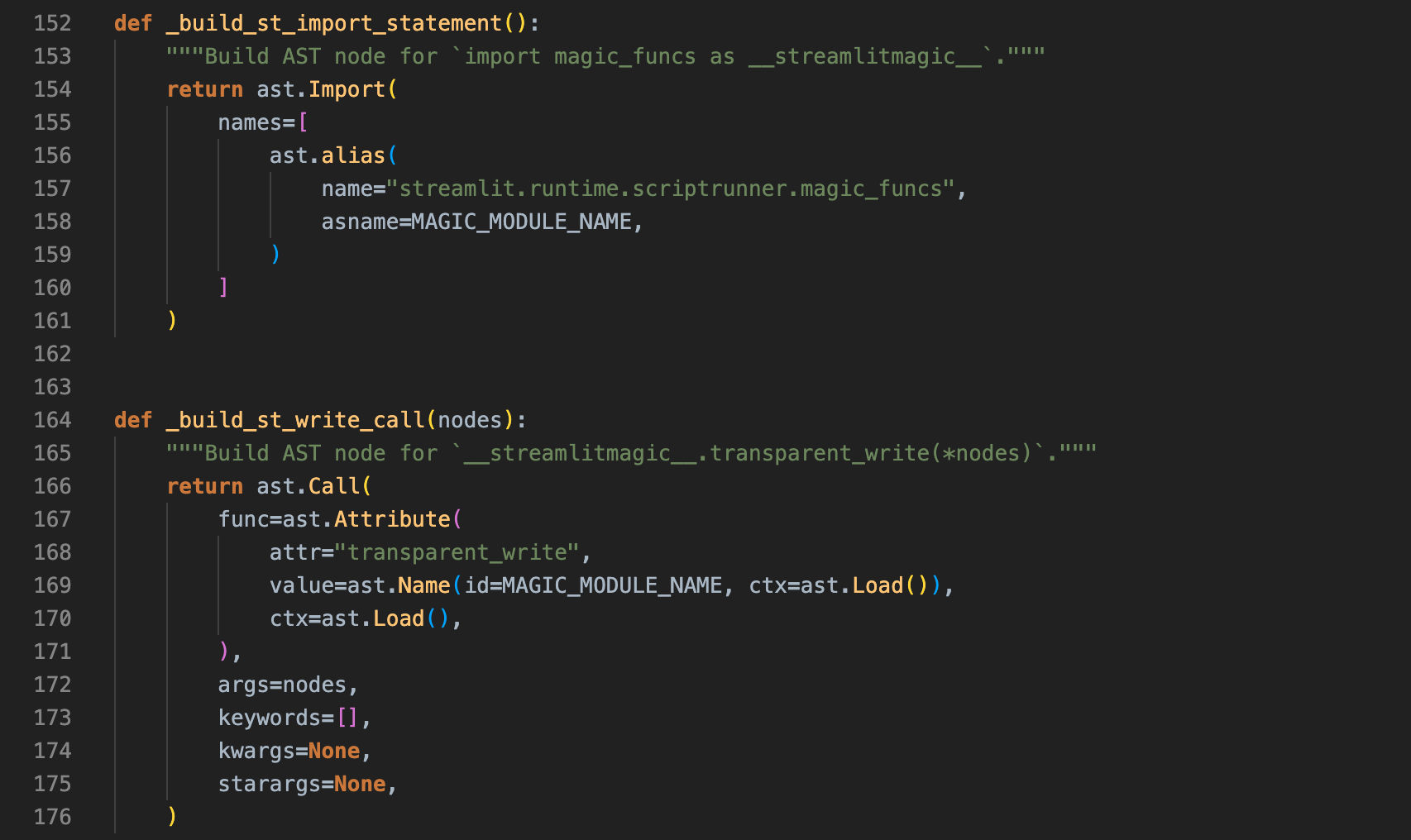
5.3 实现 st.cache_data 和 st.cache_resource
这两个函数比较有意思,一开始我以为用户脚本是运行在一个独立进程里的,进程死掉后 cache 就没了,因此实现起来还稍微有些麻烦。而上面的 ScriptRunner 已经给我们揭示了实际上它只是一个用户脚本线程而已,那这个上下文就很好维护了,即使用户脚本退出了,也能维持 cache 实例。然而代码我还没看懂,在 ScriptRunner 里的 exec() 调用时,是屏蔽了当前线程的上下文的,给它创建了个虚拟 module:

而如果我们写这样的 case 来跑,是不行的:
global_cache = {}
module = types.ModuleType("__main__")
sys.modules["__main__"] = module
user_code = """
def cache_func(key):
if key not in global_cache:
print('cache miss')
global_cache[key] = key
return key
else:
print('cache hit')
return global_cache[key]
print(cache_func('key1'))
"""
exec(user_code, globals()) # ok!
exec(user_code, module.__dict__) # crash!!!
尝试跟踪了下 cache_data 函数的运行时堆栈,发现在 import 时,一个单例的 _data_caches 会被创建出来,它会记录 function cache 信息,其中包括一个 InMemoryCacheStorageWrapper 实例,我们尝试在这里打印调用堆栈,发现第二次执行时,这里是不会被 invoke 的,而堆栈顶部是
代码位置:streamlit/runtime/caching/cache_data_api.py

运行时堆栈:

而且这个堆栈位置是远早于用户脚本线程创建时间的。那么我们有一个合理怀疑是线程创建时,已经 import 过的 module,不会被重复导入,且能维持其实例:
import t_cache
t_cache.global_cache = {'key1': 1}
print(t_cache.global_cache)
code = """
import sys
print('t_cache' in sys.modules.keys())
print('t_cache' in globals())
import t_cache
print(t_cache.global_cache)
"""
exec(code, {})
# 输出:
{'key1': 1}
True
False
{'key1': 1}
这就很有意思了,虽然这个 cache 并未出现在 globals(),但 sys.modules 里已经被保留下来了,因此能够完成 cache 的功能。
至于 st.cache_data 和 st.cache_resource 的差异,前者在 InMemoryCacheStorageWrapper 里同时做了 memory、disk 两种方式的缓存,因此即使 memory 不够了或者失效了,还可以从 disk 恢复。而后者猜测并非 copy,而是 ref 了一份变量。代码大差不差,不多赘述。
6. 前端组件声明
挑选一个前端组件来看下具体的实现方式吧。以 st.button 为例,官方文档的示例是:
import streamlit as st
st.button("Reset", type="primary")
if st.button('Say hello'): # 这里很有意思,根据 button 的返回值来执行分支,莫非每次点击都会触发一次完整的脚本执行?
st.write('Why hello there')
else:
st.write('Goodbye')
# 我们在这里加一些耗时的代码,看看是否每次点击都会整个脚本重跑
import datetime
import time
st.write("Current time is: ", datetime.datetime.now())
time.sleep(10)
st.write("After a long wait, the time is: ", datetime.datetime.now())
图片:点击按钮前后的截图,可以发现:每次点击按钮都会重新执行整个脚本。
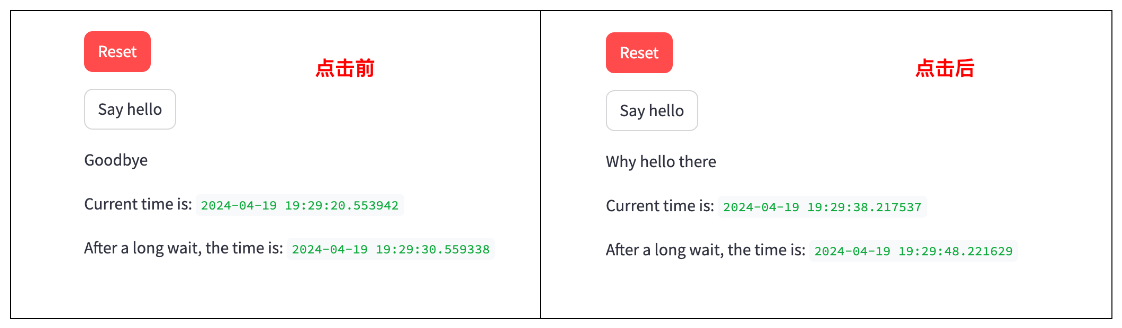
这里感觉是比较失望的,会直接限制 streamlit 只适合做数据展示的工作,无法承载较复杂的前端操作逻辑。
其具体实现方式很容易猜到,大概将会是这样子:
- 当用户脚本调用
st.button()时,后台生成一个关于 button 的描述(如长宽值、表显文本、颜色等),把该描述通过 websocket 通道丢给前端 - 前端根据描述内容,按模板绘制一个 button,并绑定 on_click 事件,一旦触发则发起一轮新的用户脚本执行过程,并把该 button id 对应的
st.button()返回值设置为 True
追踪一下代码,很容易找到其序列化 button 描述的地方。
位置:streamlit/elements/widgets/button.py
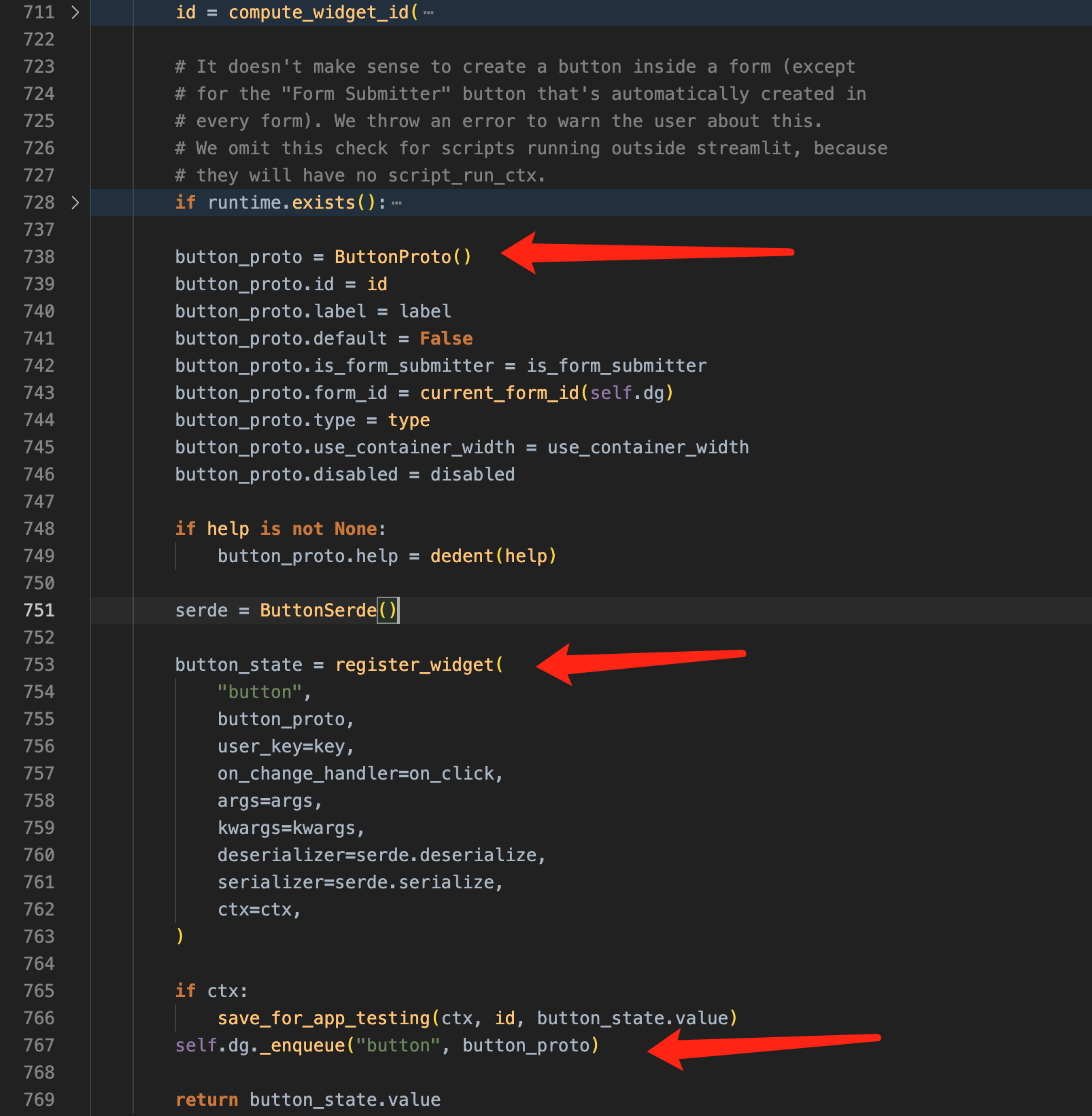
尝试捕捉一下消息序列,和猜想完全一致:
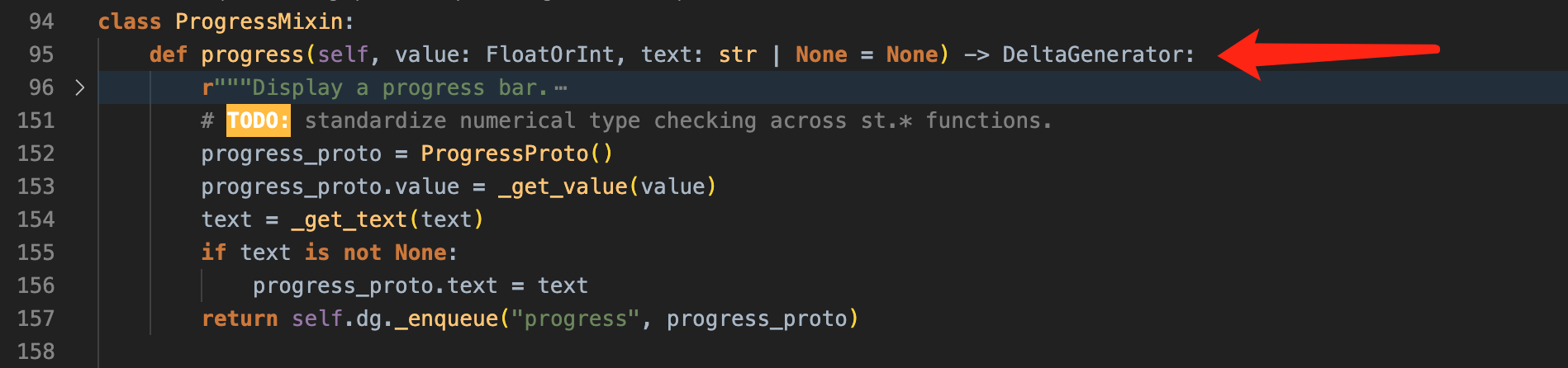
至于 st.progress() 函数,也就不难了,反正每次更新进度都需要调用一次 progress() 函数,在这里发起一次 protobuf 的序列化并发往前端就是了,没有难度:
位置:streamlit/elements/progress.py
7. 总结
整体读下来,streamlit 可读性很强,各个模块划分很清晰,前后端分离,界限明显。
- ScriptRunner 和上下文注入方式有新意,
magic commands设计不错使用起来很舒服;但线程执行的方式会带来较大的限制,不如进程来的灵活且隔离性更好 - 实现了比较全面的前端组件,使用门槛低,和常用的 python 数据套件如 numpy、pandas、matplotlib 等配合很好
然而它的缺点也非常突出:
- 可执行的粒度是整个用户脚本,无法单独重跑其中某一段代码,每次刷新页面就是一次重新执行
- 前端的各个操作是 “伪” 响应式,即使简单如按钮点击,都会触发整个脚本的重新执行
基于上面的优缺点,可以发现 streamlit 的定位非常清晰:一个快速、门槛极低的数据展示页面工具库!